Language Preparation
The official kaldi documentation on this section.
This section covers the same content as the recipe script in /local/tidigits_prepare_lang.sh
To understand this section you should first understand openFST.
The Phones
Kaldi expects a number of files to be in the data/lang/phones/ directory.
Most of them are not complex for TIDIGITS.
To facilitate the creation of this, it is useful to have a full list of phonemes. This could be created many ways. One way it to apply Awk to the lexicon (see next section).
These phone files a simple lists with one phone each line:
silence.txt,context_indep.txtandoptional_silence.txtall are made to just single like files containingsilthe silence phoneme symbol.nonsilence.txtcontains all other phonemes.
The following files would do a lot more in more complicated situations, but are simple for TIDIGITS
- sets.txt each line contains a set of phones that should be considered to be the same phoneme (i.e. a set of morphemes for one phoneme). Since in TIDIGITS this is not a concern (we don’t have access to a morpheme level transcription), each set contains just the one phoneme so all phonemes should be listed on there own line in this file. Including sil (the silence phoneme).
- disambig.txt should be created and left empty.
- extra-questions.txt should also be created and left empty.
Generating isymbols files from the phones.
Once you have a phonelist, it is very easy to enumerate it to create the isymbols file required for the phoneme-word FST.
Converting Symbol Phonelist to Integer Phone Lists
Once you have a isymbols file, each of the files created in the previous set need to be converted to lists of there matching integers rather than textual symbols. The files created this way have the same name, but with a .int extension.
The perl script utils/sym2int.pl is used for this. It can take a single parameters of the symbols file, and then will take on standard in, the symbolic (.txt) phone lists, and output (on standard out), there corresponding integer forms.
silence, nonsilence, context_indep, optional_silence, disambig
all also need to be converter to colon separated list files (.csl),
these are the same as the .int files, but instead of the integer phone representation being separated by linebreaks, they are separated with colons. A simplish job for Awk/sed.
roots.txt Decision Tree Roots
Kaldi makes use of Decision Trees for some functionality. See the documentation for the why and how of this.
It require a root definition file.
For TIDIGITS is is very simple.
roots.txt contains on each line, shared split <phone-symmbol>, and has one line for each phone.
It is converted to roots.int, by converting each phone symbol to it integer representation.
Words and Out of Vocabulary Lists
A word symbol list will also need to be constructed for the FST. Again this can be generated from the lexicon (see below), with Awk.
The word symbols are simply: o, z ,1, 2, 3, 4, 6, 7, 8, 9.
To go with this Kaldi needs to be told what word to use when words that are not in the vocabulary list are found. Since no such words exist in TIDIGITS, it really doesn’t mater what it done with them. But Kaldi requires the files.
Create a oov.txt with any one word in it. (Example script uses z).
Create a oov.int with the matching integer for it.
This can be done manually,
or it could be done with sym2int on the words symbol list, created earlier.
If you arranged you word symbols so that the int form of your oov word is the same is its text form then you are either over or under thinking this, and you could copy the oov.txt to oov.int
The Lexicon
The example recipe for TIDIGITs is quiet clever about constructing the phoneme to word FST.
There script util/make_lexicon_fst.pl takes a lexicon file, and outputs a text FST file.
Each line of the Lexicon file has the format:
<word> <phoneme> <phoneme> <phonen....
i.e. one word followed by its phoneme make up, specified with space delimited symbols.
The Lexicon for TIDIGITS:
z iy r ow
o ow
1 w ah n
2 t uw
3 th r iy
4 f ao r
5 f ay v
6 s ih k s
7 s eh v ah n
8 ey t
9 n ay n
Converting Lexicon to lexicon.fst.txt: util/make_lexicon_fst.pl
The Full break-down of how to use it (which will be output if no arguments are passed to it):
Usage:
make_lexicon_fst.pl [--pron-probs] lexicon.txt [silprob silphone [sil_disambig_sym]] >lexicon.fst.txt
Creates a lexicon FST that transduces phones to words, and may allow optional silence.
Note: ordinarily, each line of lexicon.txt is: wfstcompileord phone1 phone2 ... phoneN; if the --pron-probs option is used, each line is: word pronunciation-probability phone1 phone2 ... phoneN. The probability ‘prob’ will typically be between zero and one, and note that it’s generally helpful to normalize so the largest one for each word is 1.0, but this is your responsibility. The silence disambiguation symbol,
e.g. something like #5, is used only when creating a lexicon with disambiguation symbols, e.g. L_disambig.fst, and was introduced to fix a particular case of non-determinism of decoding graphs.
Compiling the Lexicon FST: L.fst
The lexicon.fst.txt, is then compiled (fstcompile), using the isymbols and osymbols generated from the lexicon.txt, plus the silence phoneme (sil) added in the make lexicon.txt.fst step.
It’s edges are then sorted by output label using fstarcsort. (not sure why this is required.)
L_disambig.fst = L.fst
To quote the TIDIGITs recipe:
in this setup there are no “disambiguation symbols” because the lexicon contains no homophones; and there is no ‘#0’ symbol in the LM [(Language Model)] because it’s not a backoff LM, so L_disambig.fst is the same as L.fst
So L.fst is copied to L_disambig.fst
For more information on disambiguation read the documentation page.
The final lexicon FST
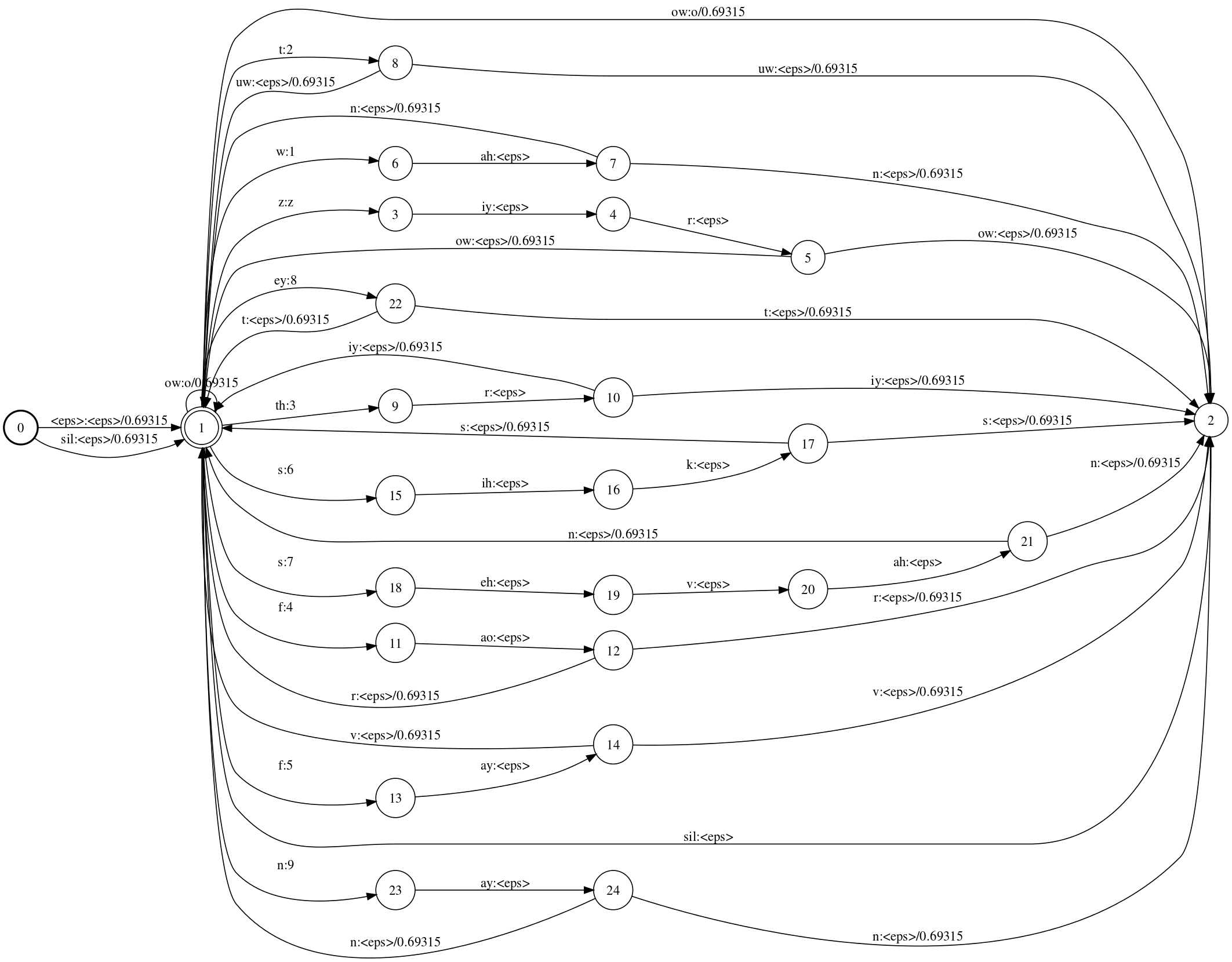
0 is the initial state (as always), and 1 is the only final state. Notice there is only one path leaving state 2 and that goes back to 1 via ‘sil’. Notice also that all states which have a transition to 2, have a identical transition to 1.
The Grammar
The Lexicon defined how Phonemes make up words. The Grammar defines how words make up a sentence. The grammar is a weighed FSA. It is expressed as a weighted FST in the example script – a FSA can be considered as a FST with input and output symbols the same.
The States
As our sentences are made up of digit sequences of length between 1 and 7, this could be re-represented as a WFSA with 8 states, 7 of which are optionally terminal, and all of which have all digits going to
It is simpler, and more real world useful, however to take the assumption that digit sequences can be of any length (greater than 1).
This can be modelled as a FSA, with just one state, which is both initial and terminal, and all edges connect to it. This is done in the example recipe
The Transitions
As a FSA each edge has one label, but as it is expressed as a FST this label is put on both input and output.
The Weights
We want to relate the weight to the probability of that transition happening. After a digit has been said there are 12 possible future actions:
- A digit from 1-9 is said
- o, pronounced Oh is said
- z, pronounced zero is said
- nothing further is said, as the sentence has ended.
It is reasonable to assume each of there 12 options is equally likely. So they each have a probability of 1/12th.
In there circumstances it is normal to work with negative log probabilities for numerical stability.
-ln(1/2)=2.48490664979.... This can just be put in to the final like of each column in the FST.
The example recipe uses an inline perl to calculate it on the fly (but is is not expressed in any more digits).
Compile and Arc Sort
The FST is compiled and arc sored just as for the lexicon.
The example calls this G.fst
The final grammar FST
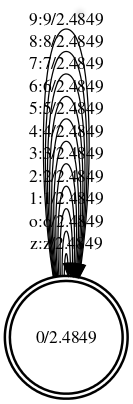
The Final Grammar Composed with Lexicon
The great beauty of working with FSTs in this way is they are compose-able. There is no need to compose them in this step – that will be done later when they are also composed with the HMM; but so that you can see what is going on, below is the grammar composed with the lexicon.
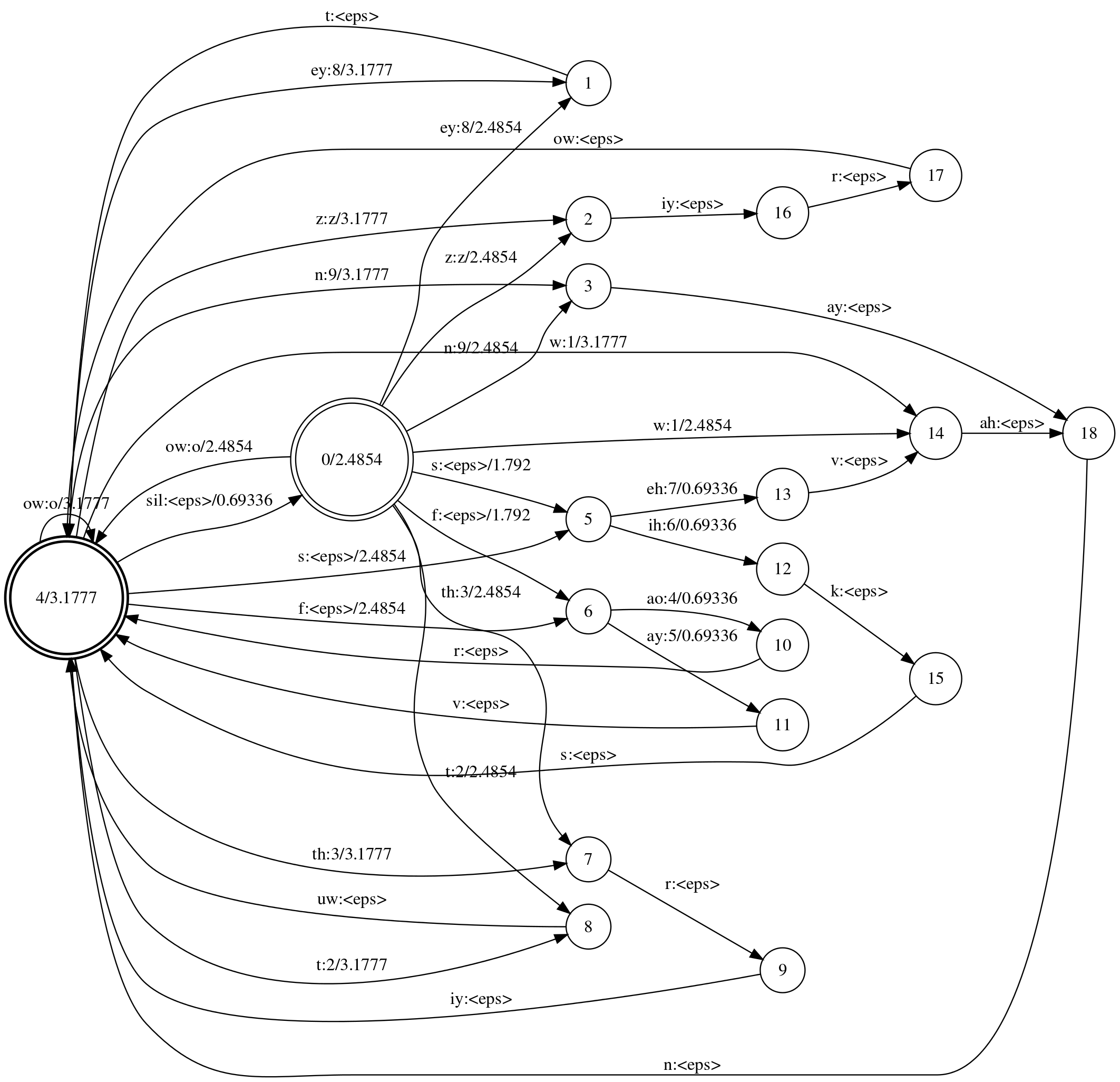
0 is the initial state. 0 and 4 are the final states. This FST maps phones (from the lexicon) to strings of words which are allowed by the Grammar. However, since the Grammar is so permissive (no restrictions at all on order of words), this looks very similar to the Lexicon FST. It is in fact equivelent to the Kleene closure of the Lexicon FST.
HMM Topology
One could say this was really part of the next step of training.
However it is covered in the sample script for this section at /local/tidigits_prepare_lang.sh.
The actual action to be taken is very simple. Understanding why takes some knowledge of HMMs.
The HMM Topology defines how the HMM that is going to be created for the Phones works. In most cases the 3 state Bakis model is used.
To get a idea what is really going on under the hood, read this page of the documentation.
In short, topo files define instructions for how to build Hidden Markov Models (HMMs) – what states are linked to others.
The topo file is expressed in a almost-XML language (not quiet XML as not all opened tags have close tags, only ones that have other elements nested inside them.). Kaldi uses this, and will eventually at some point internally produce a WFST that is the HMM. Which you might find in literature referred to as H, to go with the lexicon L and the grammar G.
In practice
All that is required is to copy the template 3 state Bakis from conf/topo.protp,
and use sed to replace NONSILENCEPHONES, and SILENCEPHONES, with space separated lists of the integer representation of the nonsilent and silent phones respectively.
Validating Everything has been done correctly so far
This step is actually carried out in run.sh rather than in the local/tidigits_prepare_lang.sh.
util/validate_lang.pl takes a single argument – the path to the lang folder.
It then validates that all things have been set up correctly.
However there are some warnings for the TIDIGITs setup.
To quote run.sh:
utils/validate_lang.pl data/lang/Note; this actually does report errors, and exits with status 1, but we’ve checked them and seen that they don’t matter (this setup doesn’t have any disambiguation symbols, and the script doesn’t like that).